python, 전처리, 통계, 가설검정, 기계학습, 회귀, 분류, 군집, 모델 학습, 모델 평가
정규성 검정(Normality Test)은 데이터가 정규분포를 따르는지 확인하는 과정이다. 많은 통계 기법이 정규성을 가정하므로, 분석 전에 이 가정이 타당한지 검증해야 한다. 다만, 정규성 검정의 목적은 “데이터가 완벽히 정규분포인가?”를 판단하는 것이 아니라 “정규분포 가정을 사용해도 분석 결과가 타당한가?”를 확인하는 것이다. 이 장에서는 시각적 방법과 통계적 검정을 통해 정규성을 평가하고, 정규성 가정이 위배될 때의 대응 전략을 학습한다.
예제: 데이터 로드
import seaborn as snsimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport scipy.stats as stats# 데이터 로드df = sns.load_dataset("penguins").dropna()print("데이터 크기:", df.shape)print("\n분석 대상 변수:")print(df.select_dtypes(include=[np.number]).columns.tolist())
데이터 크기: (333, 7)
분석 대상 변수:
['bill_length_mm', 'bill_depth_mm', 'flipper_length_mm', 'body_mass_g']
12.1 정규성 검정의 필요성
많은 통계 기법이 정규성 가정에 의존한다. 이 가정이 심각하게 위배되면 분석 결과가 부정확해질 수 있다.
정규성 가정이 필요한 통계 기법
기법
정규성 가정 대상
중요도
이유
t-검정
각 그룹의 데이터 또는 표본 평균
높음
검정 통계량이 t-분포를 따름
ANOVA
각 그룹의 잔차
높음
F-통계량의 분포 가정
선형 회귀
잔차(residuals)
매우 높음
추론과 예측 구간의 정확도
상관 분석
Pearson 상관계수
중간
검정 통계량의 분포
주성분 분석(PCA)
데이터
낮음
정규성 불필요하지만 해석 도움
정규성 검사가 필요한 상황
상황
정규성 필요 여부
이유
원 데이터 (대표본, n ≥ 30)
낮음
중심극한정리로 표본 평균이 정규분포 수렴
원 데이터 (소표본, n < 30)
매우 높음
중심극한정리 효과 미약
잔차(residuals)
매우 높음
회귀분석의 핵심 가정
비모수 검정 사용 시
불필요
분포 가정 없음
정규성 검정의 핵심은 “정규 가정을 사용해도 되는가?”를 판단하는 것이지, “데이터가 완벽히 정규분포인가?”를 확인하는 것이 아니다.
12.2 시각적 정규성 검정
통계적 검정 전에 시각적 방법으로 데이터의 분포를 확인하는 것이 중요하다. 시각적 방법은 직관적이고 분포의 특성(왜도, 첨도, 이상치)을 파악하기 쉽다.
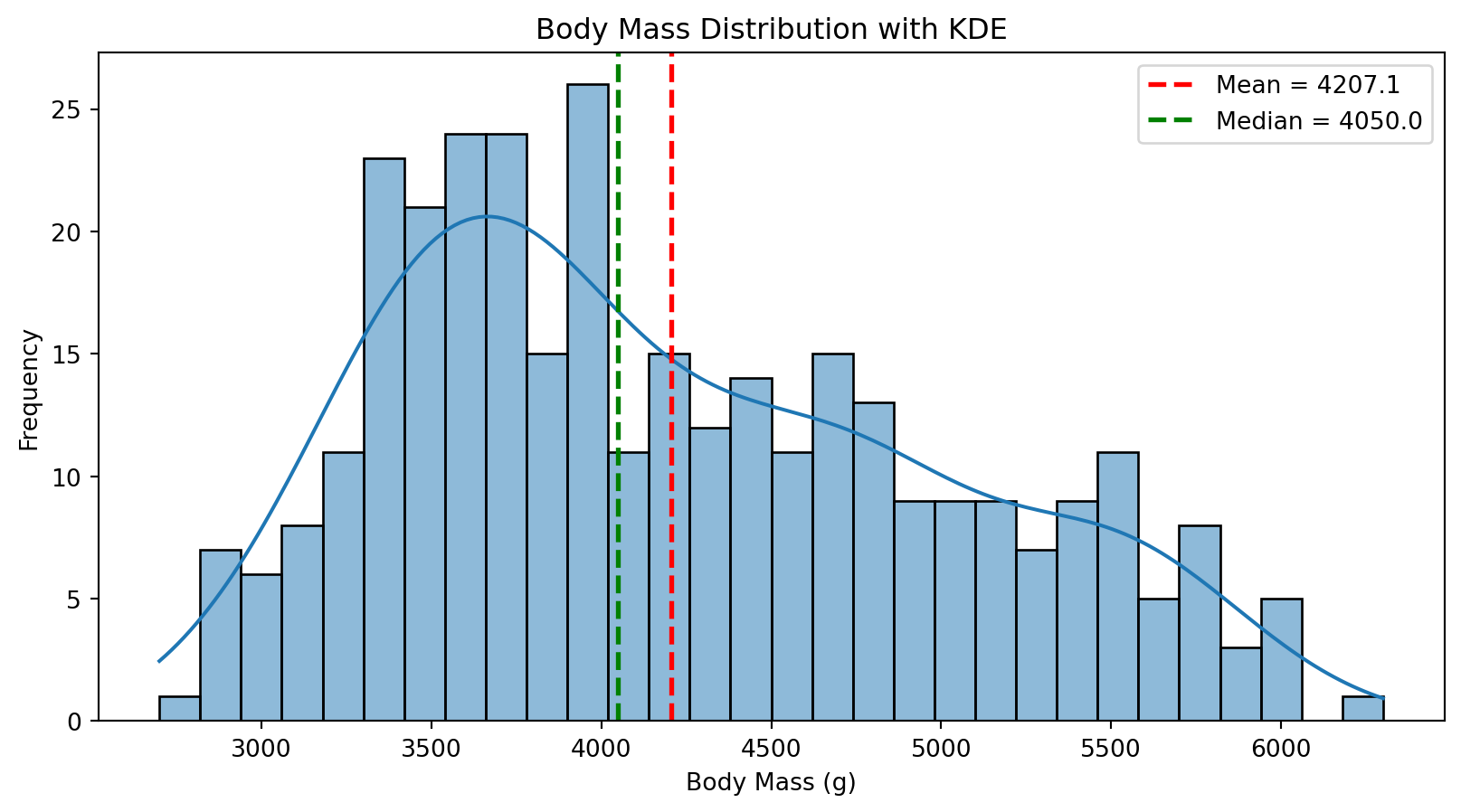
12.2.1 히스토그램과 KDE (Kernel Density Estimation)
히스토그램은 데이터의 분포 형태를 가장 간단하게 확인할 수 있는 방법이다. KDE 곡선을 함께 표시하면 연속적인 분포 형태를 더 잘 파악할 수 있다.
예제: 히스토그램 + KDE
# 체중 분포 시각화plt.figure(figsize=(10, 5))sns.histplot(df["body_mass_g"], kde=True, bins=30, edgecolor='black')plt.axvline(df["body_mass_g"].mean(), color='red', linestyle='--', linewidth=2, label=f'Mean = {df["body_mass_g"].mean():.1f}')plt.axvline(df["body_mass_g"].median(), color='green', linestyle='--', linewidth=2, label=f'Median = {df["body_mass_g"].median():.1f}')plt.title("Body Mass Distribution with KDE")plt.xlabel("Body Mass (g)")plt.ylabel("Frequency")plt.legend()plt.show()# 기술 통계량print("기술 통계량:")print(df["body_mass_g"].describe())print(f"\n왜도(Skewness): {df['body_mass_g'].skew():.3f}")print(f"첨도(Kurtosis): {df['body_mass_g'].kurtosis():.3f}")
기술 통계량:
count 333.000000
mean 4207.057057
std 805.215802
min 2700.000000
25% 3550.000000
50% 4050.000000
75% 4775.000000
max 6300.000000
Name: body_mass_g, dtype: float64
왜도(Skewness): 0.472
첨도(Kurtosis): -0.733
정규성 판단 기준
종 모양: 중앙이 높고 양 끝으로 갈수록 낮아지는 형태
대칭성: 평균과 중앙값이 유사하고 좌우 대칭
왜도: 0에 가까울수록 대칭 (|skewness| < 0.5 권장)
첨도: 3에 가까울수록 정규분포 (정규분포의 첨도 = 3)
꼬리: 양쪽 꼬리가 너무 두껍거나 얇지 않음
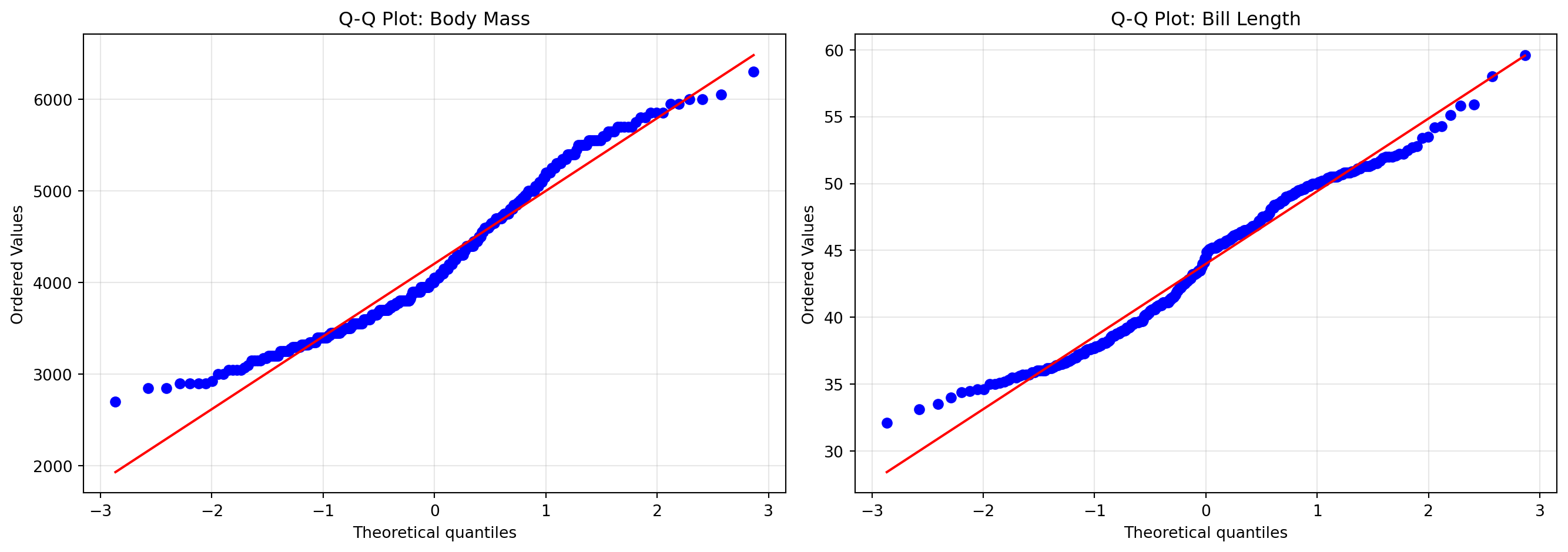
12.2.2 Q-Q Plot (Quantile-Quantile Plot)
Q-Q 플롯은 데이터의 분위수를 이론적 정규분포의 분위수와 비교하는 그래프이다. 가장 신뢰할 수 있는 시각적 정규성 검정 방법이다.
예제: Q-Q Plot
# Q-Q 플롯 생성fig, axes = plt.subplots(1, 2, figsize=(14, 5))# 체중 Q-Q 플롯stats.probplot(df["body_mass_g"], dist="norm", plot=axes[0])axes[0].set_title("Q-Q Plot: Body Mass")axes[0].grid(True, alpha=0.3)# 부리 길이 Q-Q 플롯stats.probplot(df["bill_length_mm"], dist="norm", plot=axes[1])axes[1].set_title("Q-Q Plot: Bill Length")axes[1].grid(True, alpha=0.3)plt.tight_layout()plt.show()
Q-Q Plot 해석 가이드
패턴
의미
조치
점들이 직선에 근접
정규분포에 가까움
정규성 가정 사용 가능
왼쪽 끝이 위로 이탈
왼쪽 꼬리가 두꺼움 (음의 왜도)
로그 변환 고려
오른쪽 끝이 위로 이탈
오른쪽 꼬리가 두꺼움 (양의 왜도)
로그 또는 제곱근 변환
S자 곡선
왜도가 있음
변환 또는 비모수 검정
양쪽 끝이 벗어남
첨도 문제 (꼬리가 얇거나 두꺼움)
이상치 확인
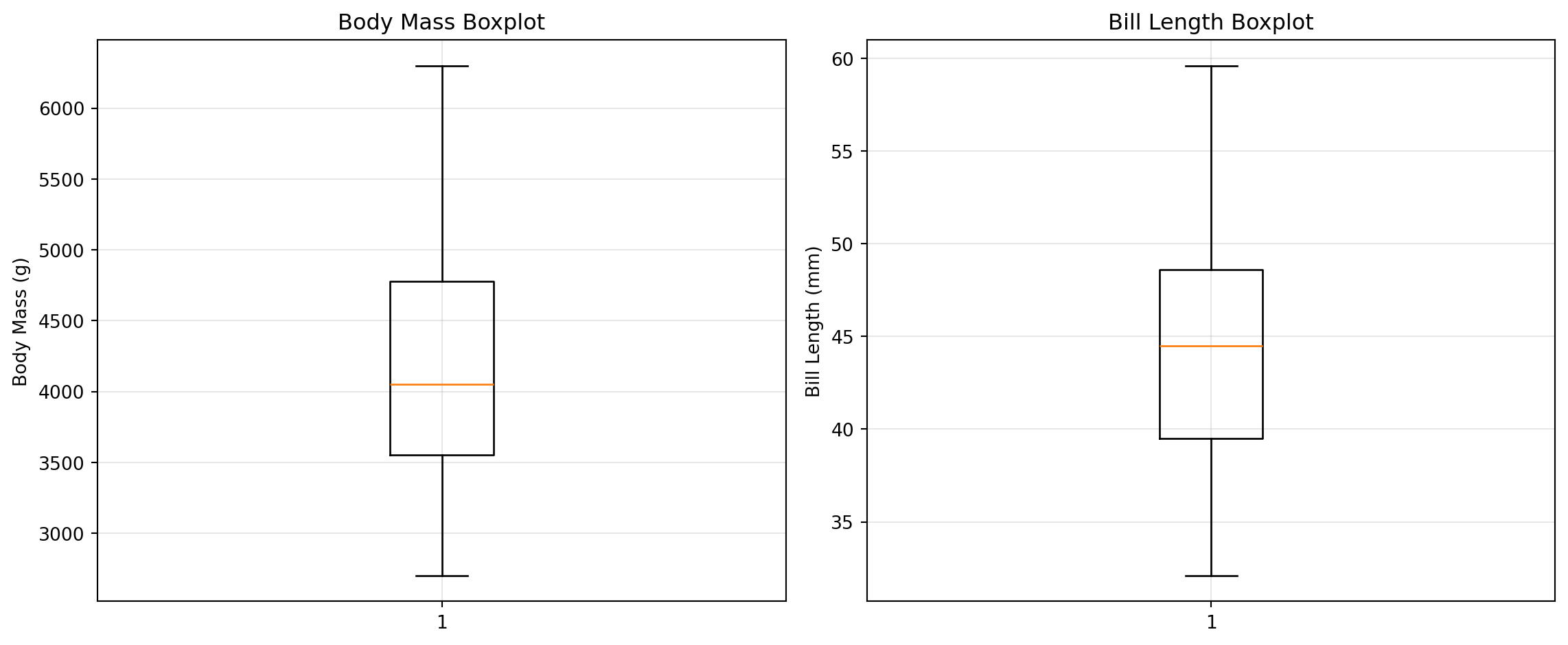
12.2.3 박스플롯
박스플롯은 이상치와 분포의 대칭성을 한눈에 확인할 수 있다.
예제: 박스플롯으로 대칭성 확인
# 박스플롯fig, axes = plt.subplots(1, 2, figsize=(12, 5))axes[0].boxplot(df["body_mass_g"], vert=True)axes[0].set_ylabel("Body Mass (g)")axes[0].set_title("Body Mass Boxplot")axes[0].grid(True, alpha=0.3)axes[1].boxplot(df["bill_length_mm"], vert=True)axes[1].set_ylabel("Bill Length (mm)")axes[1].set_title("Bill Length Boxplot")axes[1].grid(True, alpha=0.3)plt.tight_layout()plt.show()
박스가 중앙선을 중심으로 대칭이고 수염(whisker)의 길이가 비슷하면 정규분포에 가깝다.
12.3 통계적 정규성 검정
시각적 방법은 주관적일 수 있으므로, 통계적 검정으로 객관적인 판단을 보완한다.
12.3.1 주요 정규성 검정 비교
정규성 검정 방법 비교
검정
귀무가설
특징
장점
단점
권장 상황
Shapiro-Wilk
정규분포를 따름
가장 널리 사용
강력한 검정력
n > 5000에서 느림
일반적 상황 (n ≤ 5000)
Kolmogorov-Smirnov
두 분포가 같음
일반 분포 검정
다양한 분포 비교 가능
검정력 낮음
이론 분포와 비교
Anderson-Darling
정규분포를 따름
꼬리에 민감
꼬리 이상 탐지
해석 복잡
꼬리가 중요한 경우
D’Agostino-Pearson
정규분포를 따름
왜도·첨도 기반
중대형 표본에 적합
소표본에서 불안정
n ≥ 50
Jarque-Bera
정규분포를 따름
시계열 데이터용
계산 간단
대표본에서만 유효
시계열 분석
12.3.2 Shapiro-Wilk 검정
Shapiro-Wilk 검정은 가장 널리 사용되는 정규성 검정으로, 소표본부터 중표본까지 우수한 검정력을 보인다.
가설 설정
H₀ (귀무가설): 데이터가 정규분포를 따른다
H₁ (대립가설): 데이터가 정규분포를 따르지 않는다
예제: Shapiro-Wilk 검정
from scipy.stats import shapiro# 체중에 대한 정규성 검정stat, p_value = shapiro(df["body_mass_g"])print("Shapiro-Wilk Test: Body Mass")print(f"검정 통계량(W): {stat:.4f}")print(f"p-value: {p_value:.4f}")print(f"유의수준 0.05 기준: ", end="")if p_value >0.05:print("정규분포를 따른다고 볼 수 있음 (H₀ 채택)")else:print("정규분포를 따르지 않음 (H₀ 기각)")
Shapiro-Wilk Test: Body Mass
검정 통계량(W): 0.9580
p-value: 0.0000
유의수준 0.05 기준: 정규분포를 따르지 않음 (H₀ 기각)
여러 변수에 대한 검정
# 여러 변수 검정numeric_cols = ["bill_length_mm", "bill_depth_mm", "flipper_length_mm", "body_mass_g"]print("\n=== 정규성 검정 결과 요약 ===")results = []for col in numeric_cols: stat, p_value = shapiro(df[col]) results.append({"Variable": col,"W-statistic": round(stat, 4),"p-value": round(p_value, 4),"Normal?": "Yes"if p_value >0.05else"No" })results_df = pd.DataFrame(results)print(results_df.to_string(index=False))
=== 정규성 검정 결과 요약 ===
Variable W-statistic p-value Normal?
bill_length_mm 0.9743 0.0 No
bill_depth_mm 0.9733 0.0 No
flipper_length_mm 0.9517 0.0 No
body_mass_g 0.9580 0.0 No
12.3.3 Kolmogorov-Smirnov 검정
Kolmogorov-Smirnov (K-S) 검정은 데이터의 누적분포함수(CDF)를 이론적 분포와 비교한다.
예제: Kolmogorov-Smirnov 검정
from scipy.stats import kstest# 정규분포와 비교 (표준화 필요)data_standardized = (df["body_mass_g"] - df["body_mass_g"].mean()) / df["body_mass_g"].std()stat, p_value = kstest(data_standardized, 'norm')print("Kolmogorov-Smirnov Test: Body Mass")print(f"검정 통계량(D): {stat:.4f}")print(f"p-value: {p_value:.4f}")print(f"유의수준 0.05 기준: ", end="")if p_value >0.05:print("정규분포를 따른다고 볼 수 있음")else:print("정규분포를 따르지 않음")
Kolmogorov-Smirnov Test: Body Mass
검정 통계량(D): 0.1057
p-value: 0.0011
유의수준 0.05 기준: 정규분포를 따르지 않음
12.3.4 Anderson-Darling 검정
Anderson-Darling 검정은 분포의 꼬리 부분에 더 많은 가중치를 두어 극단값의 정규성을 엄격히 평가한다.
예제: Anderson-Darling 검정
from scipy.stats import anderson# Anderson-Darling 검정result = anderson(df["body_mass_g"], dist="norm")print("Anderson-Darling Test: Body Mass")print(f"검정 통계량: {result.statistic:.4f}")print("\n유의수준별 임계값:")for i, (sig_level, crit_val) inenumerate(zip(result.significance_level, result.critical_values)):print(f" {sig_level}%: {crit_val:.4f} ", end="")if result.statistic < crit_val:print("(정규분포 가정 가능)")else:print("(정규분포 기각)")
Anderson-Darling 검정은 p-value 대신 임계값과 비교한다. 검정 통계량이 임계값보다 작으면 정규성을 가정할 수 있다.
12.3.5 D’Agostino-Pearson 검정
D’Agostino-Pearson 검정은 왜도와 첨도를 동시에 고려하여 정규성을 평가한다.
예제: D’Agostino-Pearson 검정
from scipy.stats import normaltest# D'Agostino-Pearson 검정stat, p_value = normaltest(df["body_mass_g"])print("D'Agostino-Pearson Test: Body Mass")print(f"검정 통계량(K²): {stat:.4f}")print(f"p-value: {p_value:.4f}")print(f"유의수준 0.05 기준: ", end="")if p_value >0.05:print("정규분포를 따른다고 볼 수 있음")else:print("정규분포를 따르지 않음")
D'Agostino-Pearson Test: Body Mass
검정 통계량(K²): 30.4642
p-value: 0.0000
유의수준 0.05 기준: 정규분포를 따르지 않음
12.4 표본 크기와 p-value의 함정
표본 크기가 커지면 정규성 검정이 작은 편차에도 민감하게 반응하여 거의 항상 귀무가설을 기각한다. 이는 통계적으로 유의하지만 실무적으로는 무의미한 결과일 수 있다.
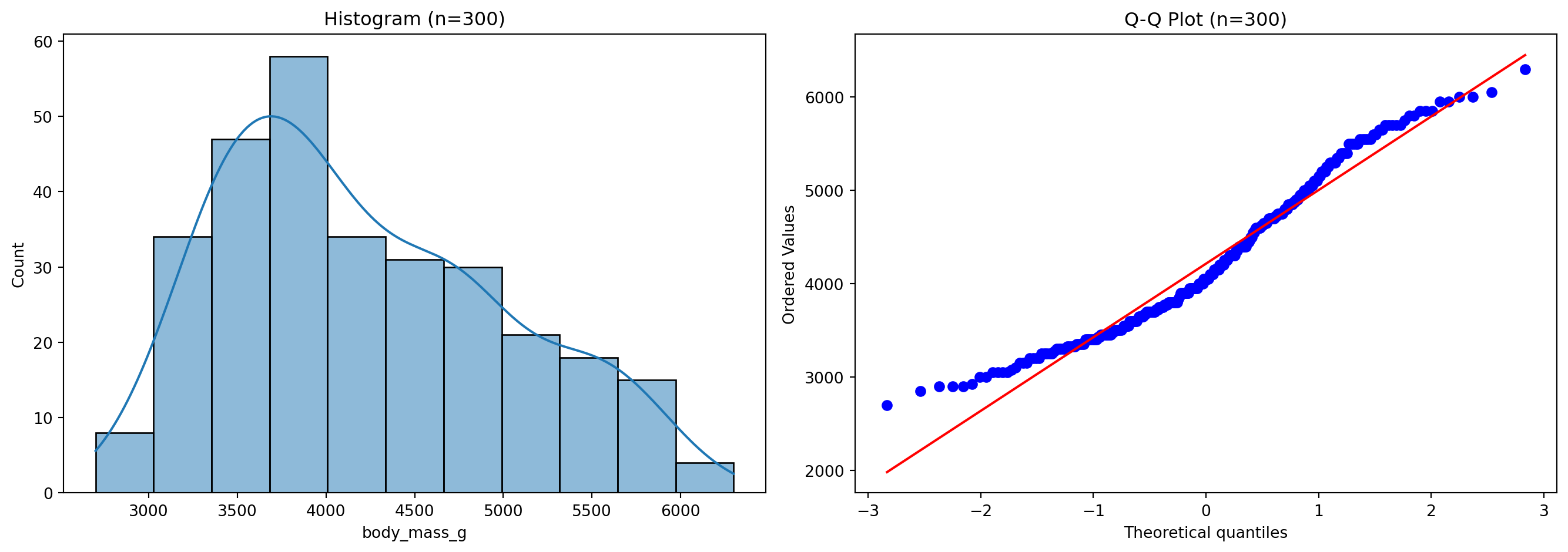
예제: 표본 크기 효과
# 다양한 표본 크기로 검정sample_sizes = [30, 100, 300]print("=== 표본 크기에 따른 Shapiro-Wilk 검정 ===\n")for n in sample_sizes: sample = df["body_mass_g"].sample(n, random_state=42) stat, p_value = shapiro(sample)print(f"n = {n:3d}: W = {stat:.4f}, p-value = {p_value:.4f} ", end="")print("→ 정규"if p_value >0.05else"→ 비정규")
=== 표본 크기에 따른 Shapiro-Wilk 검정 ===
n = 30: W = 0.9579, p-value = 0.2734 → 정규
n = 100: W = 0.9458, p-value = 0.0004 → 비정규
n = 300: W = 0.9592, p-value = 0.0000 → 비정규
큰 표본에서의 대응
표본 크기
p-value 해석
권장 조치
n < 30
p-value 중요
통계적 검정 결과 우선
30 ≤ n < 100
p-value + 시각화
둘 다 고려
n ≥ 100
시각화 중요
실무적 판단 우선
n ≥ 300
거의 항상 기각
중심극한정리 의존
핵심: 큰 표본에서는 통계적으로 비정규라도 중심극한정리에 의해 표본 평균이 정규분포에 수렴하므로 실무적으로 문제없는 경우가 많다.
Shapiro-Wilk: p-value = 0.0000
→ 통계적으로는 비정규이지만 시각적으로는 정규에 가까움
→ 실무적 판단: 정규성 가정 사용 가능
12.5 정규성이 위배될 때의 대응 전략
정규성 검정 결과가 유의하게 비정규라면, 다음 전략 중 하나를 선택한다.
12.5.1 전략 1: 분포 변환
데이터를 변환하여 정규분포에 가깝게 만든다. 이는 5장(분포 변환)에서 학습한 내용이다.
예제: 로그 변환 후 정규성 검정
# 로그 변환log_mass = np.log(df["body_mass_g"])# 변환 전후 비교fig, axes = plt.subplots(2, 2, figsize=(14, 10))# 원본: 히스토그램sns.histplot(df["body_mass_g"], kde=True, ax=axes[0, 0])axes[0, 0].set_title("Original: Histogram")# 원본: Q-Q Plotstats.probplot(df["body_mass_g"], dist="norm", plot=axes[0, 1])axes[0, 1].set_title("Original: Q-Q Plot")# 로그 변환: 히스토그램sns.histplot(log_mass, kde=True, ax=axes[1, 0])axes[1, 0].set_title("Log Transformed: Histogram")# 로그 변환: Q-Q Plotstats.probplot(log_mass, dist="norm", plot=axes[1, 1])axes[1, 1].set_title("Log Transformed: Q-Q Plot")plt.tight_layout()plt.show()# 검정 비교print("=== 변환 전후 Shapiro-Wilk 검정 ===")print(f"원본 데이터: W = {shapiro(df['body_mass_g'])[0]:.4f}, p = {shapiro(df['body_mass_g'])[1]:.4f}")print(f"로그 변환: W = {shapiro(log_mass)[0]:.4f}, p = {shapiro(log_mass)[1]:.4f}")
=== 변환 전후 Shapiro-Wilk 검정 ===
원본 데이터: W = 0.9580, p = 0.0000
로그 변환: W = 0.9755, p = 0.0000
주요 변환 방법
로그 변환: 양의 왜도를 줄임 (가장 흔히 사용)
제곱근 변환: 로그보다 약한 변환
Box-Cox 변환: 최적의 λ 자동 추정
Yeo-Johnson 변환: 0과 음수 포함 데이터 가능
12.5.2 전략 2: 비모수 검정 사용
정규성을 가정하지 않는 비모수 검정을 사용한다.
모수 검정 vs 비모수 검정
상황
모수 검정 (정규성 가정)
비모수 검정 (분포 자유)
두 그룹 평균 비교
Independent t-test
Mann-Whitney U test
대응 표본 비교
Paired t-test
Wilcoxon signed-rank test
다집단 비교
One-way ANOVA
Kruskal-Wallis test
상관 분석
Pearson correlation
Spearman correlation
회귀 분석
Linear regression
Quantile regression
예제: t-test vs Mann-Whitney U test
from scipy.stats import ttest_ind, mannwhitneyu# 두 종의 체중 비교 (Adelie vs Gentoo)adelie = df[df["species"] =="Adelie"]["body_mass_g"]gentoo = df[df["species"] =="Gentoo"]["body_mass_g"]# 모수 검정 (t-test)t_stat, t_pval = ttest_ind(adelie, gentoo)# 비모수 검정 (Mann-Whitney U)u_stat, u_pval = mannwhitneyu(adelie, gentoo)print("=== 두 그룹 비교: Adelie vs Gentoo ===")print(f"\nt-test (모수): t = {t_stat:.4f}, p = {t_pval:.4f}")print(f"Mann-Whitney (비모수): U = {u_stat:.4f}, p = {u_pval:.4f}")print("\n→ 두 검정 모두 유의한 차이 발견")
=== 두 그룹 비교: Adelie vs Gentoo ===
t-test (모수): t = -23.4668, p = 0.0000
Mann-Whitney (비모수): U = 358.5000, p = 0.0000
→ 두 검정 모두 유의한 차이 발견
비모수 검정은 검정력이 약간 낮지만, 정규성 가정을 위배해도 안전하게 사용할 수 있다.
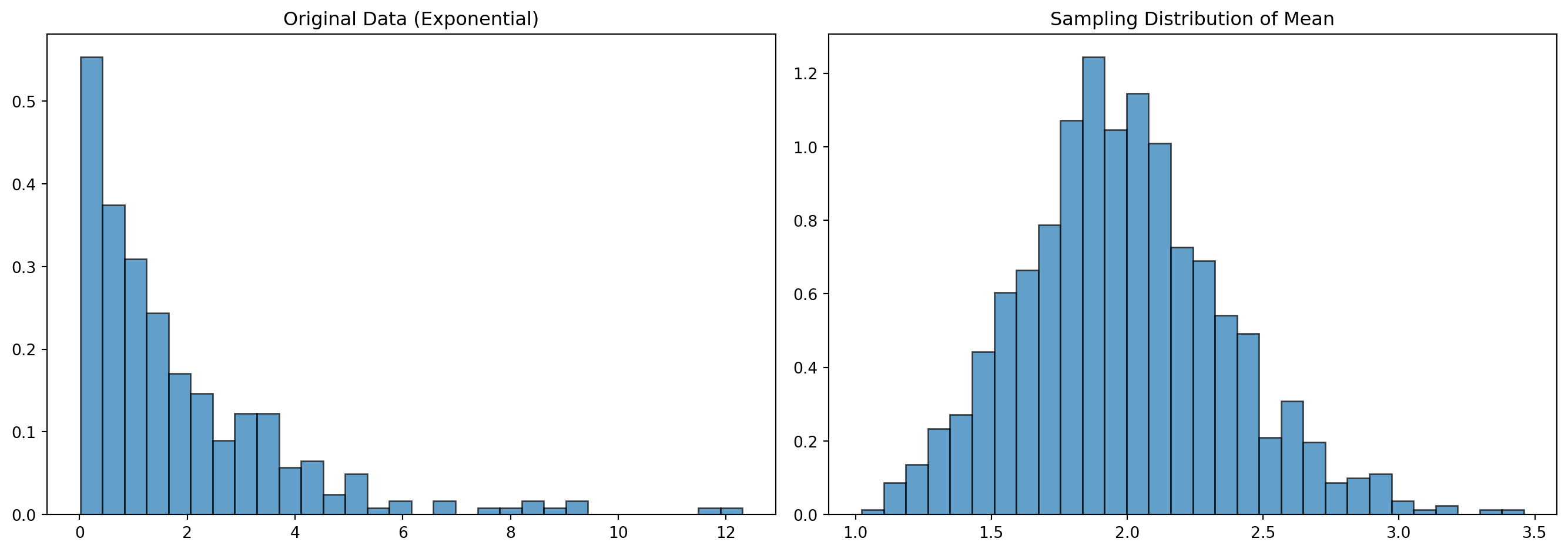
12.5.3 전략 3: 중심극한정리 활용
표본 크기가 충분히 크면(일반적으로 n ≥ 30), 원 데이터가 비정규라도 표본 평균은 정규분포에 수렴한다.
중심극한정리 적용 조건
표본 크기 n ≥ 30 (분포가 심하게 왜곡되지 않은 경우)
독립성 만족
극단적인 이상치 없음
예제: 표본 평균의 정규성
# 비정규 데이터 생성 (지수분포)non_normal_data = np.random.exponential(scale=2, size=1000)# 원본 데이터 정규성 검정print("=== 원본 데이터 (지수분포) ===")print(f"Shapiro-Wilk: p = {shapiro(non_normal_data[:300])[1]:.4f} (비정규)")# 표본 평균 분포 생성sample_means = [np.random.choice(non_normal_data, size=30).mean() for _ inrange(1000)]# 표본 평균 정규성 검정print(f"\n=== 표본 평균 분포 (n=30, 1000회 반복) ===")print(f"Shapiro-Wilk: p = {shapiro(sample_means)[1]:.4f} (정규에 가까움)")# 시각화fig, axes = plt.subplots(1, 2, figsize=(14, 5))axes[0].hist(non_normal_data[:300], bins=30, density=True, alpha=0.7, edgecolor='black')axes[0].set_title("Original Data (Exponential)")axes[1].hist(sample_means, bins=30, density=True, alpha=0.7, edgecolor='black')axes[1].set_title("Sampling Distribution of Mean")plt.tight_layout()plt.show()
=== 원본 데이터 (지수분포) ===
Shapiro-Wilk: p = 0.0000 (비정규)
=== 표본 평균 분포 (n=30, 1000회 반복) ===
Shapiro-Wilk: p = 0.0000 (정규에 가까움)
12.6 요약
이 장에서는 정규성 검정의 개념, 방법, 그리고 정규성 위배 시 대응 전략을 학습했다. 주요 내용은 다음과 같다.
정규성 검정 방법 요약
방법
유형
장점
단점
권장 상황
히스토그램 + KDE
시각적
직관적, 분포 형태 파악
주관적
초기 탐색
Q-Q Plot
시각적
정규성 판단에 가장 유용
해석 연습 필요
모든 상황 (필수)
Shapiro-Wilk
통계적
검정력 우수
대표본에서 민감
n ≤ 5000
Anderson-Darling
통계적
꼬리 민감
해석 복잡
꼬리 중요 시
K-S
통계적
다양한 분포 비교
검정력 낮음
이론 분포 비교
정규성 위배 시 대응 전략
전략
방법
장점
단점
적용 상황
분포 변환
로그, Box-Cox 등
정규성 개선
해석 복잡해짐
왜도가 심한 경우
비모수 검정
Mann-Whitney, Kruskal-Wallis
분포 가정 불필요
검정력 낮음
소표본, 비정규
중심극한정리
대표본 활용
추가 조치 불필요
n ≥ 30 필요
충분한 표본
부트스트랩
재표본추출
분포 가정 불필요
계산 비용 높음
복잡한 통계량
실무 판단 프로세스
시각적 확인: 히스토그램, Q-Q Plot으로 분포 확인
통계적 검정: Shapiro-Wilk 등으로 객관적 평가
표본 크기 고려:
소표본 (n < 30): 정규성 매우 중요
중표본 (30 ≤ n < 100): 시각적 + 통계적 판단
대표본 (n ≥ 100): 중심극한정리 의존 가능
분석 목적 고려: 회귀의 잔차는 엄격, 평균 비교는 유연
대응 전략 선택: 변환, 비모수 검정, 또는 진행
주요 주의사항
정규성은 절대 조건이 아니며, 실무적 판단이 중요함
p-value 하나로 결정하지 말고 시각화와 함께 종합 판단
큰 표본에서는 p-value가 과민하게 반응함을 인지
정규성 검정은 수단이지 목적이 아님
정규성 검정은 통계 분석의 가정을 검증하는 중요한 단계이다. 시각적 방법과 통계적 검정을 종합적으로 활용하고, 표본 크기와 분석 목적을 고려하여 적절한 대응 전략을 선택하는 것이 중요하다. 다음 장에서는 정규성 가정을 바탕으로 한 가설검정과 신뢰구간 추정을 학습할 것이다.